PrPages is used to determine the coloured and monochrome (b/w or gray) pages of a pdf-document.
This may e.g. to get more accurate costing of copy jobs or for printing costs of company-departments.
If you only have to decide whether it should be a monochrome print or a color printout, a single coloured page in a 30-pages pdf-document can generate a much more expensive color copy from a - actually - mainly b/w copy. That hurts, of course, if you have to save money ;-)
Now back to PRPages ... Which page has coloured elements, which is completely b/w we should know using PrPages. This probably helps to reduce cost in the printing area. It would be even better, if you could extract and print the coloured pages separately.
A prospect came to me with questions regarding the described problem ... He asked me to develope an individual solution for him.
After some considerations, the free tool PDFtk came to my mind again. The command line tool PDFtk offers i.a. functions to connect single pdf-pages to a new document, to split pdf-documents into single pages, to connect single pages according to specification for a new document and much more.
PDFtk and the CMD instruction set from Microsoft for creating BAT files (yes ... the files with the extension BAT) would be enough to realize the desired individual solution free of charge.
1. PrPages
PRPages creates a csv-file with all relevant data (regarding used colors and so on) for each page of a whole pdf-document.
We need a bat(ch)-file to start PrPages with some parameters in the directory of PrPages. It can be look like this:
@echo off
if "%~1"=="" goto input1
set testvar1=%~1
IF EXIST rows.txt del rows.txt
IF EXIST rows.csv del rows.csv
prpages %testvar1% E 00 rows.csv
ren rows.csv rows.txt
goto end
:input1
echo The 1st parameter for the input-file (for example: "c:\temp\catalogue.pdf") is missing!
:end
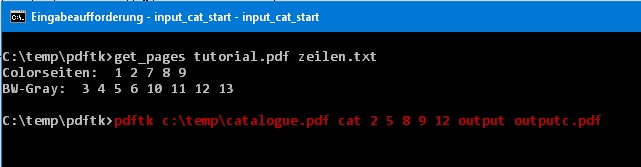
This bat(ch)-file - let us call it get_colors.bat - called from the cmd-line (eg. "c:\temp\pdftk\>") could be look like this:
get_colors c:\temp\catalogue.pdf
The result should be a file rows.txt with a content similar to this one:
c:\temp\pdftk\catalogue.pdf;1;842;595;color;
c:\temp\pdftk\catalogue.pdf;2;842;595;color;
c:\temp\pdftk\catalogue.pdf;3;842;595;bw/gray;
c:\temp\pdftk\catalogue.pdf;4;842;595;bw/gray;
c:\temp\pdftk\catalogue.pdf;5;842;595;bw/gray;
2. Doing the real page extraction and reconcatenation into two new separated files (color and b/w)
For this we use PDFtk that provides functionality for separating and merging individual files.
On the command-line this can eg. look like this:
pdftk c:\temp\catalogue.pdf cat 2 5 8 9 12 output outputc.pdf

So we have to extract from the file rows.txt the coloured pages using the determined page-numbers. With these page-numbers we have to concatenate a string as a new parameter for PDFtk ...
The most important line in the bat(ch)-file for this functionality is:
for /f "tokens=2 delims=;" %%i in ('findstr /C:";color;" %testvar2%') do echo %%i>>color.txt
tokens=2 ... means the second column in the csv-file rows.txt. The second column contains the page number.
delims=; ... determines the used field separator.
findstr ... is an internal cmd-command for string searches in files.
;color; ... shall be now the string we're searching for in rows.txt.
%testvar2% ... this variable contains the parameter from calling the bat(ch)-file (eg. the csv-file rows.txt).
do echo %%i>>color.txt ... the output of the page numbers in lines with the string ";color;" will be in color.txt.
color.txt now contains the page numbers in a vertical arrangement.
From this file content (the numbers) we have to create a string:
FOR /F %%i in (color.txt) do call set "Myvar1=%%Myvar1%% %%i"
for ... means loop-processing.
%%i ... this variable contains the currently read line content (the page number).
color.txt ... this is our file with the page numbers for the coloured pages.
Myvar1 ... this is the name of the variable for the string with the page numbers.
%%Myvar1%% ... means the content of variable Myvar1
Myvar1=%%Myvar1%% %%i ... means Myvar1=previous content of Myvar1 and additionally the new content (the next number).
At the end of the loop-processing Myvar1 contains a string like 2 5 8 9 12 for example.
Finally the last important line in the bat file can look like this:
pdftk %testvar1% cat %Myvar1% output outputc.pdf
%testvar1% ... contains file- and path-name of the original pdf-document.
cat ... is a command from PDFtk to separate pages (single or ranges).
%Myvar1% ... contains the string with the page numbers from variable Myvar1.
output ... is a command from PDFtk to write the separated pages into a new pdf-document.
outputc.pdf ... finally this file contains the coloured pages 2, 5, 8, 9 and 12 from the sample-pdf.
Finally, the whole bat file with additionally - hopefully self-explanatory - lines.
To complete the whole process, it also includes the processing for the b/w pages:
@echo off
if "%~1"=="" goto input1
set testvar1=%~1
if "%~2"=="" goto input2
set testvar2=%~2
SET "Myvar1="
SET "Myvar2="
IF EXIST color.txt del color.txt
IF EXIST bwgray.txt del bwgray.txt
for /f "tokens=2 delims=;" %%i in ('findstr /C:";color;" %testvar2%') do echo %%i>>color.txt
for /f "tokens=2 delims=;" %%i in ('findstr /C:";bw/gray;" %testvar2%') do echo %%i>>bwgray.txt
FOR /F %%i in (color.txt) do call set "Myvar1=%%Myvar1%% %%i"
for /f %%i in (bwgray.txt) do call set "Myvar2=%%Myvar2%% %%i"
IF EXIST outputc.pdf del outputc.pdf
IF EXIST outputb.pdf del outputb.pdf
echo color pages: %Myvar1%
pdftk %testvar1% cat %Myvar1% output outputc.pdf
echo bwgray pages: %Myvar2%
pdftk %testvar1% cat %Myvar2% output outputb.pdf
goto ende
:input1
echo The 1st parameter pdf-inputfile (eg.: "c:\temp\catalogue.pdf") is missing!
goto end
:input2
echo The 2nd parameter csv-outputfile (with color data) (eg.: "c:\temp\rows.txt") is missing!
:end
The variable call of this bat-file (let us call it get_pages.bat) from the command line could be eg. look like this:
get_pages c:\temp\catalogue.pdf c:\temp\rows.txt

As a result, we get two new files from the original file (which will be preserved) - one with colored PDF pages, one with b/w pages, which can then go to the copy shop or print out on a color or b/w laserprinter.